Validation
Estimation of the treatment effect cannot be validated the same way as regular ML predictions because the true value is not available except for the experimental data. Here we focus on the internal validation methods under the assumption of unconfoundedness of potential outcomes and the treatment status conditioned on the feature set available to us.
Validation with Multiple Estimates
We can validate the methodology by comparing the estimates with other approaches, checking the consistency of estimates across different levels and cohorts.
Model Robustness for Meta Algorithms
In meta-algorithms we can assess the quality of user-level treatment effect estimation by comparing estimates from different underlying ML algorithms. We will report MSE, coverage (overlapping 95% confidence interval), uplift curve. In addition, we can split the sample within a cohort and compare the result from out-of-sample scoring and within-sample scoring.
User Level/Segment Level/Cohort Level Consistency
We can also evaluate user-level/segment level/cohort level estimation consistency by conducting T-test.
Stability between Cohorts
Treatment effect may vary from cohort to cohort but should not be too volatile. For a given cohort, we will compare the scores generated by model fit to another score with the ones generated by its own model.
Validation with Synthetic Data Sets
We can test the methodology with simulations, where we generate data with known causal and non-causal links between the outcome, treatment and some of confounding variables.
We implemented the following sets of synthetic data generation mechanisms based on [20]:
Mechanism 1
Mechanism 2
Mechanism 3
Mechanism 4
Validation with Uplift Curve (AUUC)
We can validate the estimation by evaluating and comparing the uplift gains with AUUC (Area Under Uplift Curve), it calculates cumulative gains. Please find more details in meta_learners_with_synthetic_data.ipynb example notebook.
from causalml.dataset import *
from causalml.metrics import *
# Single simulation
train_preds, valid_preds = get_synthetic_preds_holdout(simulate_nuisance_and_easy_treatment,
n=50000,
valid_size=0.2)
# Cumulative Gain AUUC values for a Single Simulation of Validation Data
get_synthetic_auuc(valid_preds)
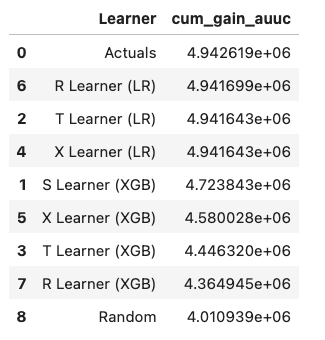
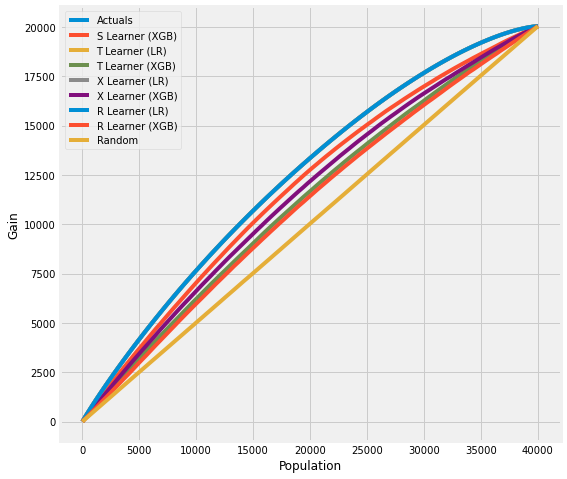
For data with skewed treatment, it is sometimes advantageous to use Targeted maximum likelihood estimation (TMLE) for ATE to generate the AUUC curve for validation, as TMLE provides a more accurate estimation of ATE. Please find validation_with_tmle.ipynb example notebook for details.
Validation with Sensitivity Analysis
Sensitivity analysis aim to check the robustness of the unconfoundeness assumption. If there is hidden bias (unobserved confounders), it determines how severe would have to be to change conclusion by examining the average treatment effect estimation.
We implemented the following methods to conduct sensitivity analysis: