DragonNet vs Meta-Learners Benchmark with IHDP + Synthetic Datasets
Dragonnet requires tensorflow. If you haven’t, please install tensorflow as follows:
pip install tensorflow
[1]:
%load_ext autoreload
%autoreload 2
[2]:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.linear_model import LogisticRegressionCV, LogisticRegression
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error as mse
from scipy.stats import entropy
import warnings
from causalml.inference.meta import LRSRegressor
from causalml.inference.meta import XGBTRegressor, MLPTRegressor
from causalml.inference.meta import BaseXRegressor, BaseRRegressor, BaseSRegressor, BaseTRegressor
from causalml.inference.tf import DragonNet
from causalml.match import NearestNeighborMatch, MatchOptimizer, create_table_one
from causalml.propensity import ElasticNetPropensityModel
from causalml.dataset.regression import *
from causalml.metrics import *
import os, sys
%matplotlib inline
warnings.filterwarnings('ignore')
plt.style.use('fivethirtyeight')
sns.set_palette('Paired')
plt.rcParams['figure.figsize'] = (12,8)
IHDP semi-synthetic dataset
Hill introduced a semi-synthetic dataset constructed from the Infant Health and Development Program (IHDP). This dataset is based on a randomized experiment investigating the effect of home visits by specialists on future cognitive scores. The data has 747 observations (rows). The IHDP simulation is considered the de-facto standard benchmark for neural network treatment effect estimation methods.
The original paper uses 1000 realizations from the NCPI package, but for illustration purposes, we use 1 dataset (realization) as an example below.
[3]:
df = pd.read_csv(f'data/ihdp_npci_3.csv', header=None)
cols = ["treatment", "y_factual", "y_cfactual", "mu0", "mu1"] + [f'x{i}' for i in range(1,26)]
df.columns = cols
[4]:
df.shape
[4]:
(747, 30)
[5]:
df.head()
[5]:
| treatment | y_factual | y_cfactual | mu0 | mu1 | x1 | x2 | x3 | x4 | x5 | ... | x16 | x17 | x18 | x19 | x20 | x21 | x22 | x23 | x24 | x25 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 5.931652 | 3.500591 | 2.253801 | 7.136441 | -0.528603 | -0.343455 | 1.128554 | 0.161703 | -0.316603 | ... | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 2.175966 | 5.952101 | 1.257592 | 6.553022 | -1.736945 | -1.802002 | 0.383828 | 2.244320 | -0.629189 | ... | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 2.180294 | 7.175734 | 2.384100 | 7.192645 | -0.807451 | -0.202946 | -0.360898 | -0.879606 | 0.808706 | ... | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 3.587662 | 7.787537 | 4.009365 | 7.712456 | 0.390083 | 0.596582 | -1.850350 | -0.879606 | -0.004017 | ... | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 2.372618 | 5.461871 | 2.481631 | 7.232739 | -1.045229 | -0.602710 | 0.011465 | 0.161703 | 0.683672 | ... | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 30 columns
[6]:
pd.Series(df['treatment']).value_counts(normalize=True)
[6]:
0 0.813922
1 0.186078
Name: treatment, dtype: float64
[7]:
X = df.loc[:,'x1':]
treatment = df['treatment']
y = df['y_factual']
tau = df.apply(lambda d: d['y_factual'] - d['y_cfactual'] if d['treatment']==1
else d['y_cfactual'] - d['y_factual'],
axis=1)
[9]:
p_model = ElasticNetPropensityModel()
p = p_model.fit_predict(X, treatment)
[10]:
s_learner = BaseSRegressor(LGBMRegressor())
s_ate = s_learner.estimate_ate(X, treatment, y)[0]
s_ite = s_learner.fit_predict(X, treatment, y)
t_learner = BaseTRegressor(LGBMRegressor())
t_ate = t_learner.estimate_ate(X, treatment, y)[0][0]
t_ite = t_learner.fit_predict(X, treatment, y)
x_learner = BaseXRegressor(LGBMRegressor())
x_ate = x_learner.estimate_ate(X, treatment, y, p)[0][0]
x_ite = x_learner.fit_predict(X, treatment, y, p)
r_learner = BaseRRegressor(LGBMRegressor())
r_ate = r_learner.estimate_ate(X, treatment, y, p)[0][0]
r_ite = r_learner.fit_predict(X, treatment, y, p)
[11]:
dragon = DragonNet(neurons_per_layer=200, targeted_reg=True)
dragon_ite = dragon.fit_predict(X, treatment, y, return_components=False)
dragon_ate = dragon_ite.mean()
Epoch 1/30
10/10 [==============================] - 5s 156ms/step - loss: 1790.3492 - regression_loss: 864.6742 - binary_classification_loss: 41.3394 - treatment_accuracy: 0.7299 - track_epsilon: 0.0063 - val_loss: 242.1589 - val_regression_loss: 87.0011 - val_binary_classification_loss: 32.6806 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0055
Epoch 2/30
10/10 [==============================] - 0s 7ms/step - loss: 311.9302 - regression_loss: 135.2392 - binary_classification_loss: 32.8420 - treatment_accuracy: 0.8643 - track_epsilon: 0.0059 - val_loss: 230.2209 - val_regression_loss: 79.8030 - val_binary_classification_loss: 34.3533 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0047
Epoch 3/30
10/10 [==============================] - 0s 6ms/step - loss: 274.1216 - regression_loss: 118.1561 - binary_classification_loss: 31.3200 - treatment_accuracy: 0.8169 - track_epsilon: 0.0044 - val_loss: 238.4452 - val_regression_loss: 82.0530 - val_binary_classification_loss: 36.2376 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0049
Epoch 4/30
10/10 [==============================] - 0s 6ms/step - loss: 205.4690 - regression_loss: 85.9585 - binary_classification_loss: 27.2440 - treatment_accuracy: 0.8606 - track_epsilon: 0.0053 - val_loss: 235.7122 - val_regression_loss: 78.5524 - val_binary_classification_loss: 39.7929 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0057
Epoch 1/300
10/10 [==============================] - 1s 41ms/step - loss: 195.6840 - regression_loss: 80.7820 - binary_classification_loss: 27.7316 - treatment_accuracy: 0.8497 - track_epsilon: 0.0054 - val_loss: 207.3960 - val_regression_loss: 67.6306 - val_binary_classification_loss: 38.1122 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0177
Epoch 2/300
10/10 [==============================] - 0s 6ms/step - loss: 183.9956 - regression_loss: 75.3269 - binary_classification_loss: 26.4330 - treatment_accuracy: 0.8622 - track_epsilon: 0.0182 - val_loss: 197.0267 - val_regression_loss: 64.0559 - val_binary_classification_loss: 38.4298 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0117
Epoch 3/300
10/10 [==============================] - 0s 6ms/step - loss: 178.8321 - regression_loss: 72.7892 - binary_classification_loss: 26.7587 - treatment_accuracy: 0.8555 - track_epsilon: 0.0081 - val_loss: 195.6257 - val_regression_loss: 63.5609 - val_binary_classification_loss: 38.2400 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0073
Epoch 4/300
10/10 [==============================] - 0s 6ms/step - loss: 177.0419 - regression_loss: 71.8475 - binary_classification_loss: 27.1255 - treatment_accuracy: 0.8521 - track_epsilon: 0.0091 - val_loss: 200.6521 - val_regression_loss: 65.3493 - val_binary_classification_loss: 37.6216 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0082
Epoch 5/300
10/10 [==============================] - 0s 6ms/step - loss: 198.0597 - regression_loss: 82.4320 - binary_classification_loss: 27.0536 - treatment_accuracy: 0.8497 - track_epsilon: 0.0076 - val_loss: 194.4365 - val_regression_loss: 63.1230 - val_binary_classification_loss: 37.8598 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0064
Epoch 6/300
10/10 [==============================] - 0s 5ms/step - loss: 174.1273 - regression_loss: 70.2306 - binary_classification_loss: 27.7639 - treatment_accuracy: 0.8460 - track_epsilon: 0.0075 - val_loss: 194.3751 - val_regression_loss: 63.1176 - val_binary_classification_loss: 37.9318 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0100
Epoch 7/300
10/10 [==============================] - 0s 6ms/step - loss: 187.2528 - regression_loss: 77.2338 - binary_classification_loss: 26.6574 - treatment_accuracy: 0.8545 - track_epsilon: 0.0094 - val_loss: 193.4222 - val_regression_loss: 62.8618 - val_binary_classification_loss: 37.8932 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0100
Epoch 8/300
10/10 [==============================] - 0s 6ms/step - loss: 179.5122 - regression_loss: 72.3961 - binary_classification_loss: 28.5867 - treatment_accuracy: 0.8357 - track_epsilon: 0.0110 - val_loss: 196.3768 - val_regression_loss: 63.7690 - val_binary_classification_loss: 37.5827 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0094
Epoch 9/300
10/10 [==============================] - 0s 6ms/step - loss: 180.4453 - regression_loss: 74.0497 - binary_classification_loss: 26.0765 - treatment_accuracy: 0.8582 - track_epsilon: 0.0077 - val_loss: 192.4576 - val_regression_loss: 62.1838 - val_binary_classification_loss: 37.8295 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0104
Epoch 10/300
10/10 [==============================] - 0s 6ms/step - loss: 159.2664 - regression_loss: 63.3608 - binary_classification_loss: 26.5497 - treatment_accuracy: 0.8544 - track_epsilon: 0.0118 - val_loss: 192.8072 - val_regression_loss: 62.6150 - val_binary_classification_loss: 38.0268 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0147
Epoch 11/300
10/10 [==============================] - 0s 6ms/step - loss: 157.3967 - regression_loss: 62.1042 - binary_classification_loss: 27.1641 - treatment_accuracy: 0.8496 - track_epsilon: 0.0139 - val_loss: 190.8307 - val_regression_loss: 61.5484 - val_binary_classification_loss: 37.7637 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0105
Epoch 12/300
10/10 [==============================] - 0s 6ms/step - loss: 171.3408 - regression_loss: 69.0045 - binary_classification_loss: 27.2531 - treatment_accuracy: 0.8468 - track_epsilon: 0.0092 - val_loss: 190.0314 - val_regression_loss: 61.2129 - val_binary_classification_loss: 37.7777 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0087
Epoch 13/300
10/10 [==============================] - 0s 6ms/step - loss: 162.0215 - regression_loss: 62.9260 - binary_classification_loss: 30.3296 - treatment_accuracy: 0.8189 - track_epsilon: 0.0084 - val_loss: 189.2025 - val_regression_loss: 60.8970 - val_binary_classification_loss: 37.7255 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0126
Epoch 14/300
10/10 [==============================] - 0s 6ms/step - loss: 173.8554 - regression_loss: 70.6637 - binary_classification_loss: 26.2371 - treatment_accuracy: 0.8540 - track_epsilon: 0.0126 - val_loss: 189.1865 - val_regression_loss: 60.8833 - val_binary_classification_loss: 37.6686 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0099
Epoch 15/300
10/10 [==============================] - 0s 6ms/step - loss: 157.4061 - regression_loss: 63.5324 - binary_classification_loss: 24.4340 - treatment_accuracy: 0.8718 - track_epsilon: 0.0093 - val_loss: 186.8761 - val_regression_loss: 60.0529 - val_binary_classification_loss: 37.9590 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0089
Epoch 16/300
10/10 [==============================] - 0s 6ms/step - loss: 172.2053 - regression_loss: 69.6182 - binary_classification_loss: 26.8678 - treatment_accuracy: 0.8502 - track_epsilon: 0.0080 - val_loss: 188.4488 - val_regression_loss: 60.4575 - val_binary_classification_loss: 37.6228 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0113
Epoch 17/300
10/10 [==============================] - 0s 6ms/step - loss: 162.3663 - regression_loss: 65.2318 - binary_classification_loss: 26.0364 - treatment_accuracy: 0.8562 - track_epsilon: 0.0105 - val_loss: 186.5810 - val_regression_loss: 59.7591 - val_binary_classification_loss: 37.6693 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0114
Epoch 18/300
10/10 [==============================] - 0s 6ms/step - loss: 163.8466 - regression_loss: 65.5130 - binary_classification_loss: 26.7643 - treatment_accuracy: 0.8503 - track_epsilon: 0.0119 - val_loss: 190.8825 - val_regression_loss: 62.1830 - val_binary_classification_loss: 37.9718 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0087
Epoch 19/300
10/10 [==============================] - 0s 6ms/step - loss: 167.6180 - regression_loss: 68.2214 - binary_classification_loss: 25.3027 - treatment_accuracy: 0.8620 - track_epsilon: 0.0066 - val_loss: 185.6225 - val_regression_loss: 59.4746 - val_binary_classification_loss: 37.6837 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0060
Epoch 20/300
10/10 [==============================] - 0s 6ms/step - loss: 168.5476 - regression_loss: 68.3371 - binary_classification_loss: 25.8652 - treatment_accuracy: 0.8578 - track_epsilon: 0.0079 - val_loss: 184.5200 - val_regression_loss: 59.2031 - val_binary_classification_loss: 37.5099 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0098
Epoch 21/300
10/10 [==============================] - 0s 6ms/step - loss: 157.9161 - regression_loss: 63.3173 - binary_classification_loss: 25.2899 - treatment_accuracy: 0.8634 - track_epsilon: 0.0083 - val_loss: 185.0839 - val_regression_loss: 59.1452 - val_binary_classification_loss: 37.5366 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0079
Epoch 22/300
10/10 [==============================] - 0s 6ms/step - loss: 160.4739 - regression_loss: 63.1629 - binary_classification_loss: 28.0595 - treatment_accuracy: 0.8358 - track_epsilon: 0.0086 - val_loss: 183.9351 - val_regression_loss: 59.1525 - val_binary_classification_loss: 37.5067 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0066
Epoch 23/300
10/10 [==============================] - 0s 6ms/step - loss: 155.0890 - regression_loss: 60.5116 - binary_classification_loss: 28.0962 - treatment_accuracy: 0.8349 - track_epsilon: 0.0046 - val_loss: 183.6170 - val_regression_loss: 58.7653 - val_binary_classification_loss: 37.2800 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0051
Epoch 24/300
10/10 [==============================] - 0s 6ms/step - loss: 149.4288 - regression_loss: 58.8520 - binary_classification_loss: 25.9568 - treatment_accuracy: 0.8546 - track_epsilon: 0.0052 - val_loss: 188.7191 - val_regression_loss: 60.7916 - val_binary_classification_loss: 37.1127 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0069
Epoch 25/300
10/10 [==============================] - 0s 6ms/step - loss: 156.3095 - regression_loss: 61.0641 - binary_classification_loss: 28.1708 - treatment_accuracy: 0.8315 - track_epsilon: 0.0080 - val_loss: 182.5451 - val_regression_loss: 58.6875 - val_binary_classification_loss: 37.3179 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0075
Epoch 26/300
10/10 [==============================] - 0s 6ms/step - loss: 154.8900 - regression_loss: 61.1673 - binary_classification_loss: 26.2975 - treatment_accuracy: 0.8542 - track_epsilon: 0.0059 - val_loss: 184.6580 - val_regression_loss: 59.6472 - val_binary_classification_loss: 37.4789 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0040
Epoch 27/300
10/10 [==============================] - 0s 6ms/step - loss: 153.7275 - regression_loss: 60.6342 - binary_classification_loss: 26.5628 - treatment_accuracy: 0.8494 - track_epsilon: 0.0054 - val_loss: 187.6736 - val_regression_loss: 60.4940 - val_binary_classification_loss: 37.1448 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0046
Epoch 28/300
10/10 [==============================] - 0s 6ms/step - loss: 159.4707 - regression_loss: 63.5524 - binary_classification_loss: 26.3749 - treatment_accuracy: 0.8515 - track_epsilon: 0.0043 - val_loss: 185.6613 - val_regression_loss: 60.3003 - val_binary_classification_loss: 37.4100 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0041
Epoch 29/300
10/10 [==============================] - 0s 6ms/step - loss: 144.6116 - regression_loss: 57.2770 - binary_classification_loss: 24.2153 - treatment_accuracy: 0.8699 - track_epsilon: 0.0037 - val_loss: 183.7683 - val_regression_loss: 58.8389 - val_binary_classification_loss: 37.2161 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0046
Epoch 30/300
10/10 [==============================] - 0s 6ms/step - loss: 156.1744 - regression_loss: 61.9692 - binary_classification_loss: 26.0622 - treatment_accuracy: 0.8516 - track_epsilon: 0.0058 - val_loss: 181.6741 - val_regression_loss: 58.3027 - val_binary_classification_loss: 37.2483 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0056
Epoch 31/300
10/10 [==============================] - 0s 6ms/step - loss: 149.5090 - regression_loss: 59.6090 - binary_classification_loss: 24.2077 - treatment_accuracy: 0.8685 - track_epsilon: 0.0052 - val_loss: 183.1471 - val_regression_loss: 58.8850 - val_binary_classification_loss: 37.3616 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0048
Epoch 32/300
10/10 [==============================] - 0s 6ms/step - loss: 158.8317 - regression_loss: 63.1364 - binary_classification_loss: 26.3766 - treatment_accuracy: 0.8524 - track_epsilon: 0.0040 - val_loss: 182.8958 - val_regression_loss: 58.5878 - val_binary_classification_loss: 37.0665 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0047
Epoch 33/300
10/10 [==============================] - 0s 6ms/step - loss: 153.5294 - regression_loss: 59.8976 - binary_classification_loss: 27.7524 - treatment_accuracy: 0.8380 - track_epsilon: 0.0065 - val_loss: 184.9241 - val_regression_loss: 59.4232 - val_binary_classification_loss: 36.8858 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0053
Epoch 34/300
10/10 [==============================] - 0s 6ms/step - loss: 149.8718 - regression_loss: 59.2581 - binary_classification_loss: 25.4000 - treatment_accuracy: 0.8586 - track_epsilon: 0.0050 - val_loss: 181.1425 - val_regression_loss: 58.2419 - val_binary_classification_loss: 37.1219 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0023
Epoch 35/300
10/10 [==============================] - 0s 6ms/step - loss: 147.3198 - regression_loss: 58.8689 - binary_classification_loss: 23.9842 - treatment_accuracy: 0.8717 - track_epsilon: 0.0020 - val_loss: 182.3788 - val_regression_loss: 58.5675 - val_binary_classification_loss: 37.1934 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0054
Epoch 36/300
10/10 [==============================] - 0s 6ms/step - loss: 143.2286 - regression_loss: 55.5299 - binary_classification_loss: 26.2675 - treatment_accuracy: 0.8521 - track_epsilon: 0.0059 - val_loss: 183.0977 - val_regression_loss: 59.1656 - val_binary_classification_loss: 37.0963 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0033
Epoch 37/300
10/10 [==============================] - 0s 6ms/step - loss: 149.7070 - regression_loss: 59.5447 - binary_classification_loss: 24.7418 - treatment_accuracy: 0.8625 - track_epsilon: 0.0023 - val_loss: 183.3780 - val_regression_loss: 58.6777 - val_binary_classification_loss: 37.0991 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0018
Epoch 38/300
10/10 [==============================] - 0s 6ms/step - loss: 156.6596 - regression_loss: 62.0057 - binary_classification_loss: 26.7843 - treatment_accuracy: 0.8461 - track_epsilon: 0.0034 - val_loss: 183.2619 - val_regression_loss: 58.6840 - val_binary_classification_loss: 36.8925 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0030
Epoch 39/300
10/10 [==============================] - 0s 6ms/step - loss: 155.1980 - regression_loss: 60.9731 - binary_classification_loss: 27.2335 - treatment_accuracy: 0.8443 - track_epsilon: 0.0027 - val_loss: 181.5153 - val_regression_loss: 58.3543 - val_binary_classification_loss: 37.0235 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0026
Epoch 40/300
10/10 [==============================] - 0s 6ms/step - loss: 148.6864 - regression_loss: 58.6236 - binary_classification_loss: 25.4435 - treatment_accuracy: 0.8563 - track_epsilon: 0.0023 - val_loss: 181.4140 - val_regression_loss: 58.1816 - val_binary_classification_loss: 36.9654 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0040
Epoch 00040: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-06.
Epoch 41/300
10/10 [==============================] - 0s 6ms/step - loss: 144.7339 - regression_loss: 56.2116 - binary_classification_loss: 26.5446 - treatment_accuracy: 0.8501 - track_epsilon: 0.0048 - val_loss: 180.4425 - val_regression_loss: 57.9971 - val_binary_classification_loss: 36.8370 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0046
Epoch 42/300
10/10 [==============================] - 0s 6ms/step - loss: 152.6819 - regression_loss: 59.9780 - binary_classification_loss: 26.7807 - treatment_accuracy: 0.8460 - track_epsilon: 0.0035 - val_loss: 181.0754 - val_regression_loss: 58.0677 - val_binary_classification_loss: 36.8611 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0022
Epoch 43/300
10/10 [==============================] - 0s 6ms/step - loss: 141.4455 - regression_loss: 55.1271 - binary_classification_loss: 25.5353 - treatment_accuracy: 0.8533 - track_epsilon: 0.0021 - val_loss: 181.6914 - val_regression_loss: 58.2652 - val_binary_classification_loss: 36.9244 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0029
Epoch 44/300
10/10 [==============================] - 0s 6ms/step - loss: 143.5718 - regression_loss: 54.9356 - binary_classification_loss: 27.7278 - treatment_accuracy: 0.8368 - track_epsilon: 0.0035 - val_loss: 182.9616 - val_regression_loss: 58.7127 - val_binary_classification_loss: 36.7605 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0030
Epoch 45/300
10/10 [==============================] - 0s 6ms/step - loss: 148.0318 - regression_loss: 58.2297 - binary_classification_loss: 25.4171 - treatment_accuracy: 0.8623 - track_epsilon: 0.0028 - val_loss: 182.2657 - val_regression_loss: 58.7829 - val_binary_classification_loss: 36.9492 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0031
Epoch 46/300
10/10 [==============================] - 0s 6ms/step - loss: 148.2912 - regression_loss: 58.4527 - binary_classification_loss: 25.4111 - treatment_accuracy: 0.8550 - track_epsilon: 0.0034 - val_loss: 181.4299 - val_regression_loss: 58.1758 - val_binary_classification_loss: 36.8661 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0024
Epoch 47/300
10/10 [==============================] - 0s 6ms/step - loss: 149.8918 - regression_loss: 57.9189 - binary_classification_loss: 28.0705 - treatment_accuracy: 0.8318 - track_epsilon: 0.0019 - val_loss: 181.7516 - val_regression_loss: 58.2234 - val_binary_classification_loss: 36.8086 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0017
Epoch 48/300
10/10 [==============================] - 0s 6ms/step - loss: 143.9826 - regression_loss: 56.0217 - binary_classification_loss: 25.9636 - treatment_accuracy: 0.8518 - track_epsilon: 0.0018 - val_loss: 183.2366 - val_regression_loss: 58.7730 - val_binary_classification_loss: 36.7622 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0020
Epoch 00048: ReduceLROnPlateau reducing learning rate to 2.499999936844688e-06.
Epoch 49/300
10/10 [==============================] - 0s 6ms/step - loss: 141.9178 - regression_loss: 54.9617 - binary_classification_loss: 26.0167 - treatment_accuracy: 0.8551 - track_epsilon: 0.0025 - val_loss: 181.6692 - val_regression_loss: 58.2019 - val_binary_classification_loss: 36.8163 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0035
Epoch 50/300
10/10 [==============================] - 0s 6ms/step - loss: 154.0470 - regression_loss: 60.6821 - binary_classification_loss: 26.7084 - treatment_accuracy: 0.8442 - track_epsilon: 0.0037 - val_loss: 181.5136 - val_regression_loss: 58.1967 - val_binary_classification_loss: 36.7926 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0030
Epoch 51/300
10/10 [==============================] - 0s 6ms/step - loss: 154.2879 - regression_loss: 61.1156 - binary_classification_loss: 25.9554 - treatment_accuracy: 0.8530 - track_epsilon: 0.0026 - val_loss: 181.1187 - val_regression_loss: 58.0944 - val_binary_classification_loss: 36.7854 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0019
Epoch 52/300
10/10 [==============================] - 0s 6ms/step - loss: 147.1910 - regression_loss: 57.9212 - binary_classification_loss: 25.5444 - treatment_accuracy: 0.8585 - track_epsilon: 0.0019 - val_loss: 180.9492 - val_regression_loss: 58.0477 - val_binary_classification_loss: 36.8212 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0023
Epoch 53/300
10/10 [==============================] - 0s 6ms/step - loss: 144.5095 - regression_loss: 57.1991 - binary_classification_loss: 24.5623 - treatment_accuracy: 0.8633 - track_epsilon: 0.0025 - val_loss: 181.2697 - val_regression_loss: 58.0844 - val_binary_classification_loss: 36.8072 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0025
Epoch 54/300
10/10 [==============================] - 0s 6ms/step - loss: 149.1749 - regression_loss: 58.6545 - binary_classification_loss: 26.4255 - treatment_accuracy: 0.8508 - track_epsilon: 0.0027 - val_loss: 181.6855 - val_regression_loss: 58.2050 - val_binary_classification_loss: 36.8246 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0024
Epoch 55/300
10/10 [==============================] - 0s 6ms/step - loss: 143.3488 - regression_loss: 57.4108 - binary_classification_loss: 22.5247 - treatment_accuracy: 0.8810 - track_epsilon: 0.0018 - val_loss: 181.5240 - val_regression_loss: 58.1889 - val_binary_classification_loss: 36.8670 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0017
Epoch 56/300
10/10 [==============================] - 0s 6ms/step - loss: 145.3050 - regression_loss: 57.0797 - binary_classification_loss: 25.3895 - treatment_accuracy: 0.8567 - track_epsilon: 0.0020 - val_loss: 181.2868 - val_regression_loss: 58.1061 - val_binary_classification_loss: 36.7694 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0020
Epoch 57/300
10/10 [==============================] - 0s 6ms/step - loss: 150.1354 - regression_loss: 58.8804 - binary_classification_loss: 26.4138 - treatment_accuracy: 0.8482 - track_epsilon: 0.0023 - val_loss: 181.1185 - val_regression_loss: 58.1035 - val_binary_classification_loss: 36.8033 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0027
Epoch 58/300
10/10 [==============================] - 0s 6ms/step - loss: 145.2017 - regression_loss: 57.0173 - binary_classification_loss: 25.5667 - treatment_accuracy: 0.8535 - track_epsilon: 0.0028 - val_loss: 181.2872 - val_regression_loss: 58.0891 - val_binary_classification_loss: 36.7888 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0023
Epoch 59/300
10/10 [==============================] - 0s 6ms/step - loss: 147.7799 - regression_loss: 57.4570 - binary_classification_loss: 26.7010 - treatment_accuracy: 0.8456 - track_epsilon: 0.0022 - val_loss: 181.2169 - val_regression_loss: 58.0942 - val_binary_classification_loss: 36.7608 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0024
Epoch 00059: ReduceLROnPlateau reducing learning rate to 1.249999968422344e-06.
Epoch 60/300
10/10 [==============================] - 0s 6ms/step - loss: 143.9625 - regression_loss: 56.2486 - binary_classification_loss: 25.4459 - treatment_accuracy: 0.8584 - track_epsilon: 0.0021 - val_loss: 180.9821 - val_regression_loss: 58.0493 - val_binary_classification_loss: 36.7809 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0018
Epoch 61/300
10/10 [==============================] - 0s 6ms/step - loss: 145.4550 - regression_loss: 55.9254 - binary_classification_loss: 27.6142 - treatment_accuracy: 0.8356 - track_epsilon: 0.0018 - val_loss: 181.0581 - val_regression_loss: 58.0568 - val_binary_classification_loss: 36.7708 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0018
Epoch 62/300
10/10 [==============================] - 0s 6ms/step - loss: 146.6129 - regression_loss: 57.8608 - binary_classification_loss: 24.9736 - treatment_accuracy: 0.8610 - track_epsilon: 0.0019 - val_loss: 181.3456 - val_regression_loss: 58.1192 - val_binary_classification_loss: 36.7725 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0019
Epoch 63/300
10/10 [==============================] - 0s 6ms/step - loss: 148.2220 - regression_loss: 58.4927 - binary_classification_loss: 25.3438 - treatment_accuracy: 0.8560 - track_epsilon: 0.0019 - val_loss: 181.4519 - val_regression_loss: 58.1659 - val_binary_classification_loss: 36.7662 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0019
Epoch 64/300
10/10 [==============================] - 0s 6ms/step - loss: 140.0457 - regression_loss: 53.7192 - binary_classification_loss: 26.7202 - treatment_accuracy: 0.8449 - track_epsilon: 0.0018 - val_loss: 181.4884 - val_regression_loss: 58.1761 - val_binary_classification_loss: 36.7904 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0018
Epoch 00064: ReduceLROnPlateau reducing learning rate to 6.24999984211172e-07.
Epoch 65/300
10/10 [==============================] - 0s 6ms/step - loss: 138.7515 - regression_loss: 54.9897 - binary_classification_loss: 22.9222 - treatment_accuracy: 0.8764 - track_epsilon: 0.0019 - val_loss: 181.4227 - val_regression_loss: 58.1461 - val_binary_classification_loss: 36.7599 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0021
Epoch 66/300
10/10 [==============================] - 0s 6ms/step - loss: 150.2262 - regression_loss: 59.0825 - binary_classification_loss: 26.3098 - treatment_accuracy: 0.8488 - track_epsilon: 0.0021 - val_loss: 181.3573 - val_regression_loss: 58.1316 - val_binary_classification_loss: 36.7465 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0022
Epoch 67/300
10/10 [==============================] - 0s 5ms/step - loss: 149.6757 - regression_loss: 59.4637 - binary_classification_loss: 24.7313 - treatment_accuracy: 0.8603 - track_epsilon: 0.0021 - val_loss: 181.3223 - val_regression_loss: 58.1212 - val_binary_classification_loss: 36.7481 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0021
Epoch 68/300
10/10 [==============================] - 0s 5ms/step - loss: 151.1728 - regression_loss: 60.0713 - binary_classification_loss: 25.0154 - treatment_accuracy: 0.8615 - track_epsilon: 0.0021 - val_loss: 181.1846 - val_regression_loss: 58.0904 - val_binary_classification_loss: 36.7660 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0020
Epoch 69/300
10/10 [==============================] - 0s 6ms/step - loss: 148.2535 - regression_loss: 59.0331 - binary_classification_loss: 24.1994 - treatment_accuracy: 0.8658 - track_epsilon: 0.0021 - val_loss: 181.2948 - val_regression_loss: 58.1039 - val_binary_classification_loss: 36.7439 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0023
Epoch 00069: ReduceLROnPlateau reducing learning rate to 3.12499992105586e-07.
Epoch 70/300
10/10 [==============================] - 0s 6ms/step - loss: 145.3151 - regression_loss: 57.0691 - binary_classification_loss: 25.4983 - treatment_accuracy: 0.8584 - track_epsilon: 0.0023 - val_loss: 181.3544 - val_regression_loss: 58.1245 - val_binary_classification_loss: 36.7449 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0023
Epoch 71/300
10/10 [==============================] - 0s 6ms/step - loss: 150.1866 - regression_loss: 57.9752 - binary_classification_loss: 28.1966 - treatment_accuracy: 0.8297 - track_epsilon: 0.0023 - val_loss: 181.2958 - val_regression_loss: 58.1128 - val_binary_classification_loss: 36.7442 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0022
Epoch 72/300
10/10 [==============================] - 0s 6ms/step - loss: 144.9820 - regression_loss: 57.4340 - binary_classification_loss: 24.4047 - treatment_accuracy: 0.8619 - track_epsilon: 0.0022 - val_loss: 181.3424 - val_regression_loss: 58.1227 - val_binary_classification_loss: 36.7440 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0023
Epoch 73/300
10/10 [==============================] - 0s 6ms/step - loss: 148.8112 - regression_loss: 58.0125 - binary_classification_loss: 26.8692 - treatment_accuracy: 0.8447 - track_epsilon: 0.0022 - val_loss: 181.3199 - val_regression_loss: 58.1187 - val_binary_classification_loss: 36.7438 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0021
Epoch 74/300
10/10 [==============================] - 0s 6ms/step - loss: 144.3984 - regression_loss: 56.9031 - binary_classification_loss: 24.6382 - treatment_accuracy: 0.8624 - track_epsilon: 0.0021 - val_loss: 181.3810 - val_regression_loss: 58.1361 - val_binary_classification_loss: 36.7440 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0021
Epoch 00074: ReduceLROnPlateau reducing learning rate to 1.56249996052793e-07.
Epoch 75/300
10/10 [==============================] - 0s 6ms/step - loss: 147.5547 - regression_loss: 57.7667 - binary_classification_loss: 26.1622 - treatment_accuracy: 0.8478 - track_epsilon: 0.0021 - val_loss: 181.3161 - val_regression_loss: 58.1183 - val_binary_classification_loss: 36.7473 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0021
Epoch 76/300
10/10 [==============================] - 0s 6ms/step - loss: 140.5001 - regression_loss: 53.5784 - binary_classification_loss: 27.3214 - treatment_accuracy: 0.8388 - track_epsilon: 0.0021 - val_loss: 181.2723 - val_regression_loss: 58.1086 - val_binary_classification_loss: 36.7488 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0022
Epoch 77/300
10/10 [==============================] - 0s 6ms/step - loss: 143.8736 - regression_loss: 55.9839 - binary_classification_loss: 26.1250 - treatment_accuracy: 0.8466 - track_epsilon: 0.0022 - val_loss: 181.2639 - val_regression_loss: 58.1073 - val_binary_classification_loss: 36.7513 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0021
Epoch 78/300
10/10 [==============================] - 0s 6ms/step - loss: 146.6917 - regression_loss: 58.5758 - binary_classification_loss: 23.5315 - treatment_accuracy: 0.8700 - track_epsilon: 0.0022 - val_loss: 181.2961 - val_regression_loss: 58.1147 - val_binary_classification_loss: 36.7518 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0022
Epoch 79/300
10/10 [==============================] - 0s 6ms/step - loss: 143.4007 - regression_loss: 54.8006 - binary_classification_loss: 27.7054 - treatment_accuracy: 0.8383 - track_epsilon: 0.0021 - val_loss: 181.3115 - val_regression_loss: 58.1188 - val_binary_classification_loss: 36.7477 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0021
Epoch 00079: ReduceLROnPlateau reducing learning rate to 7.81249980263965e-08.
Epoch 80/300
10/10 [==============================] - 0s 6ms/step - loss: 145.6183 - regression_loss: 57.3271 - binary_classification_loss: 25.1687 - treatment_accuracy: 0.8574 - track_epsilon: 0.0021 - val_loss: 181.2945 - val_regression_loss: 58.1152 - val_binary_classification_loss: 36.7475 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0021
Epoch 81/300
10/10 [==============================] - 0s 6ms/step - loss: 142.3395 - regression_loss: 54.9129 - binary_classification_loss: 26.6164 - treatment_accuracy: 0.8461 - track_epsilon: 0.0021 - val_loss: 181.3037 - val_regression_loss: 58.1177 - val_binary_classification_loss: 36.7449 - val_treatment_accuracy: 0.7244 - val_track_epsilon: 0.0022
[12]:
df_preds = pd.DataFrame([s_ite.ravel(),
t_ite.ravel(),
x_ite.ravel(),
r_ite.ravel(),
dragon_ite.ravel(),
tau.ravel(),
treatment.ravel(),
y.ravel()],
index=['S','T','X','R','dragonnet','tau','w','y']).T
df_cumgain = get_cumgain(df_preds)
[13]:
df_result = pd.DataFrame([s_ate, t_ate, x_ate, r_ate, dragon_ate, tau.mean()],
index=['S','T','X','R','dragonnet','actual'], columns=['ATE'])
df_result['MAE'] = [mean_absolute_error(t,p) for t,p in zip([s_ite, t_ite, x_ite, r_ite, dragon_ite],
[tau.values.reshape(-1,1)]*5 )
] + [None]
df_result['AUUC'] = auuc_score(df_preds)
[14]:
df_result
[14]:
| ATE | MAE | AUUC | |
|---|---|---|---|
| S | 4.054511 | 1.027666 | 0.575822 |
| T | 4.100199 | 0.980788 | 0.580929 |
| X | 4.020918 | 1.116303 | 0.564651 |
| R | 4.257976 | 1.665557 | 0.556855 |
| dragonnet | 4.006536 | 1.165061 | 0.556426 |
| actual | 4.098887 | NaN | NaN |
[15]:
plot_gain(df_preds)
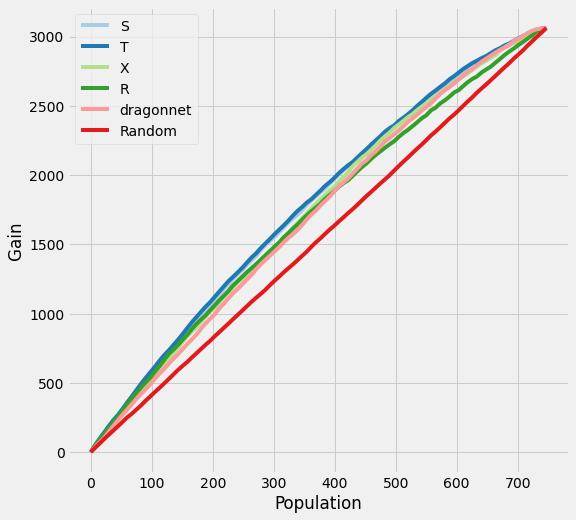
Synthetic Data Generation
[16]:
y, X, w, tau, b, e = simulate_nuisance_and_easy_treatment(n=1000)
X_train, X_val, y_train, y_val, w_train, w_val, tau_train, tau_val, b_train, b_val, e_train, e_val = \
train_test_split(X, y, w, tau, b, e, test_size=0.2, random_state=123, shuffle=True)
preds_dict_train = {}
preds_dict_valid = {}
preds_dict_train['Actuals'] = tau_train
preds_dict_valid['Actuals'] = tau_val
preds_dict_train['generated_data'] = {
'y': y_train,
'X': X_train,
'w': w_train,
'tau': tau_train,
'b': b_train,
'e': e_train}
preds_dict_valid['generated_data'] = {
'y': y_val,
'X': X_val,
'w': w_val,
'tau': tau_val,
'b': b_val,
'e': e_val}
# Predict p_hat because e would not be directly observed in real-life
p_model = ElasticNetPropensityModel()
p_hat_train = p_model.fit_predict(X_train, w_train)
p_hat_val = p_model.fit_predict(X_val, w_val)
for base_learner, label_l in zip([BaseSRegressor, BaseTRegressor, BaseXRegressor, BaseRRegressor],
['S', 'T', 'X', 'R']):
for model, label_m in zip([LinearRegression, XGBRegressor], ['LR', 'XGB']):
# RLearner will need to fit on the p_hat
if label_l != 'R':
learner = base_learner(model())
# fit the model on training data only
learner.fit(X=X_train, treatment=w_train, y=y_train)
try:
preds_dict_train['{} Learner ({})'.format(
label_l, label_m)] = learner.predict(X=X_train, p=p_hat_train).flatten()
preds_dict_valid['{} Learner ({})'.format(
label_l, label_m)] = learner.predict(X=X_val, p=p_hat_val).flatten()
except TypeError:
preds_dict_train['{} Learner ({})'.format(
label_l, label_m)] = learner.predict(X=X_train, treatment=w_train, y=y_train).flatten()
preds_dict_valid['{} Learner ({})'.format(
label_l, label_m)] = learner.predict(X=X_val, treatment=w_val, y=y_val).flatten()
else:
learner = base_learner(model())
learner.fit(X=X_train, p=p_hat_train, treatment=w_train, y=y_train)
preds_dict_train['{} Learner ({})'.format(
label_l, label_m)] = learner.predict(X=X_train).flatten()
preds_dict_valid['{} Learner ({})'.format(
label_l, label_m)] = learner.predict(X=X_val).flatten()
learner = DragonNet(verbose=False)
learner.fit(X_train, treatment=w_train, y=y_train)
preds_dict_train['DragonNet'] = learner.predict_tau(X=X_train).flatten()
preds_dict_valid['DragonNet'] = learner.predict_tau(X=X_val).flatten()
[17]:
actuals_train = preds_dict_train['Actuals']
actuals_validation = preds_dict_valid['Actuals']
synthetic_summary_train = pd.DataFrame({label: [preds.mean(), mse(preds, actuals_train)] for label, preds
in preds_dict_train.items() if 'generated' not in label.lower()},
index=['ATE', 'MSE']).T
synthetic_summary_train['Abs % Error of ATE'] = np.abs(
(synthetic_summary_train['ATE']/synthetic_summary_train.loc['Actuals', 'ATE']) - 1)
synthetic_summary_validation = pd.DataFrame({label: [preds.mean(), mse(preds, actuals_validation)]
for label, preds in preds_dict_valid.items()
if 'generated' not in label.lower()},
index=['ATE', 'MSE']).T
synthetic_summary_validation['Abs % Error of ATE'] = np.abs(
(synthetic_summary_validation['ATE']/synthetic_summary_validation.loc['Actuals', 'ATE']) - 1)
# calculate kl divergence for training
for label in synthetic_summary_train.index:
stacked_values = np.hstack((preds_dict_train[label], actuals_train))
stacked_low = np.percentile(stacked_values, 0.1)
stacked_high = np.percentile(stacked_values, 99.9)
bins = np.linspace(stacked_low, stacked_high, 100)
distr = np.histogram(preds_dict_train[label], bins=bins)[0]
distr = np.clip(distr/distr.sum(), 0.001, 0.999)
true_distr = np.histogram(actuals_train, bins=bins)[0]
true_distr = np.clip(true_distr/true_distr.sum(), 0.001, 0.999)
kl = entropy(distr, true_distr)
synthetic_summary_train.loc[label, 'KL Divergence'] = kl
# calculate kl divergence for validation
for label in synthetic_summary_validation.index:
stacked_values = np.hstack((preds_dict_valid[label], actuals_validation))
stacked_low = np.percentile(stacked_values, 0.1)
stacked_high = np.percentile(stacked_values, 99.9)
bins = np.linspace(stacked_low, stacked_high, 100)
distr = np.histogram(preds_dict_valid[label], bins=bins)[0]
distr = np.clip(distr/distr.sum(), 0.001, 0.999)
true_distr = np.histogram(actuals_validation, bins=bins)[0]
true_distr = np.clip(true_distr/true_distr.sum(), 0.001, 0.999)
kl = entropy(distr, true_distr)
synthetic_summary_validation.loc[label, 'KL Divergence'] = kl
[18]:
df_preds_train = pd.DataFrame([preds_dict_train['S Learner (LR)'].ravel(),
preds_dict_train['S Learner (XGB)'].ravel(),
preds_dict_train['T Learner (LR)'].ravel(),
preds_dict_train['T Learner (XGB)'].ravel(),
preds_dict_train['X Learner (LR)'].ravel(),
preds_dict_train['X Learner (XGB)'].ravel(),
preds_dict_train['R Learner (LR)'].ravel(),
preds_dict_train['R Learner (XGB)'].ravel(),
preds_dict_train['DragonNet'].ravel(),
preds_dict_train['generated_data']['tau'].ravel(),
preds_dict_train['generated_data']['w'].ravel(),
preds_dict_train['generated_data']['y'].ravel()],
index=['S Learner (LR)','S Learner (XGB)',
'T Learner (LR)','T Learner (XGB)',
'X Learner (LR)','X Learner (XGB)',
'R Learner (LR)','R Learner (XGB)',
'DragonNet','tau','w','y']).T
synthetic_summary_train['AUUC'] = auuc_score(df_preds_train).iloc[:-1]
[19]:
df_preds_validation = pd.DataFrame([preds_dict_valid['S Learner (LR)'].ravel(),
preds_dict_valid['S Learner (XGB)'].ravel(),
preds_dict_valid['T Learner (LR)'].ravel(),
preds_dict_valid['T Learner (XGB)'].ravel(),
preds_dict_valid['X Learner (LR)'].ravel(),
preds_dict_valid['X Learner (XGB)'].ravel(),
preds_dict_valid['R Learner (LR)'].ravel(),
preds_dict_valid['R Learner (XGB)'].ravel(),
preds_dict_valid['DragonNet'].ravel(),
preds_dict_valid['generated_data']['tau'].ravel(),
preds_dict_valid['generated_data']['w'].ravel(),
preds_dict_valid['generated_data']['y'].ravel()],
index=['S Learner (LR)','S Learner (XGB)',
'T Learner (LR)','T Learner (XGB)',
'X Learner (LR)','X Learner (XGB)',
'R Learner (LR)','R Learner (XGB)',
'DragonNet','tau','w','y']).T
synthetic_summary_validation['AUUC'] = auuc_score(df_preds_validation).iloc[:-1]
[20]:
synthetic_summary_train
[20]:
| ATE | MSE | Abs % Error of ATE | KL Divergence | AUUC | |
|---|---|---|---|---|---|
| Actuals | 0.484486 | 0.000000 | 0.000000 | 0.000000 | NaN |
| S Learner (LR) | 0.528743 | 0.044194 | 0.091349 | 3.473087 | 0.508067 |
| S Learner (XGB) | 0.358208 | 0.310652 | 0.260643 | 0.817620 | 0.544115 |
| T Learner (LR) | 0.493815 | 0.022688 | 0.019255 | 0.289978 | 0.610855 |
| T Learner (XGB) | 0.397053 | 1.350928 | 0.180466 | 1.452143 | 0.521719 |
| X Learner (LR) | 0.493815 | 0.022688 | 0.019255 | 0.289978 | 0.610855 |
| X Learner (XGB) | 0.341352 | 0.620992 | 0.295435 | 1.086086 | 0.534827 |
| R Learner (LR) | 0.457692 | 0.028116 | 0.055304 | 0.335083 | 0.614414 |
| R Learner (XGB) | 0.434709 | 4.575591 | 0.102741 | 1.907325 | 0.505088 |
| DragonNet | 0.410899 | 0.044120 | 0.151888 | 0.467829 | 0.611620 |
[21]:
synthetic_summary_validation
[21]:
| ATE | MSE | Abs % Error of ATE | KL Divergence | AUUC | |
|---|---|---|---|---|---|
| Actuals | 0.511242 | 0.000000 | 0.000000 | 0.000000 | NaN |
| S Learner (LR) | 0.528743 | 0.042236 | 0.034233 | 4.574498 | 0.495423 |
| S Learner (XGB) | 0.434208 | 0.260496 | 0.150680 | 0.854890 | 0.544206 |
| T Learner (LR) | 0.541503 | 0.025840 | 0.059191 | 0.686602 | 0.604712 |
| T Learner (XGB) | 0.483404 | 0.679398 | 0.054452 | 1.215394 | 0.526918 |
| X Learner (LR) | 0.541503 | 0.025840 | 0.059191 | 0.686602 | 0.604712 |
| X Learner (XGB) | 0.330427 | 0.344865 | 0.353678 | 1.227041 | 0.536599 |
| R Learner (LR) | 0.510236 | 0.030801 | 0.001967 | 0.654228 | 0.608133 |
| R Learner (XGB) | 0.417823 | 1.990451 | 0.182730 | 1.650560 | 0.504991 |
| DragonNet | 0.462146 | 0.043679 | 0.096032 | 0.825673 | 0.605744 |
[22]:
plot_gain(df_preds_train)
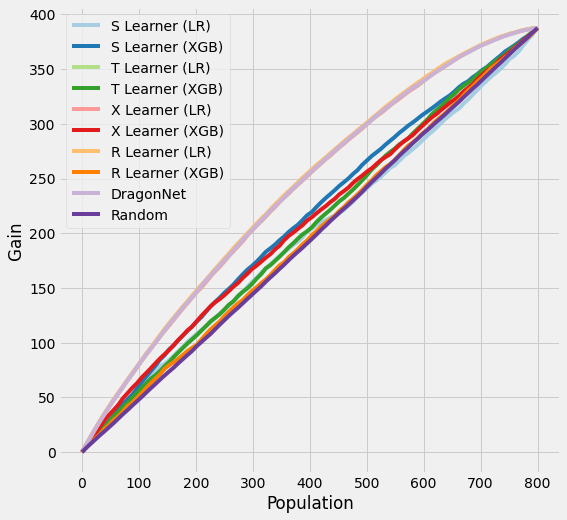
[23]:
plot_gain(df_preds_validation)
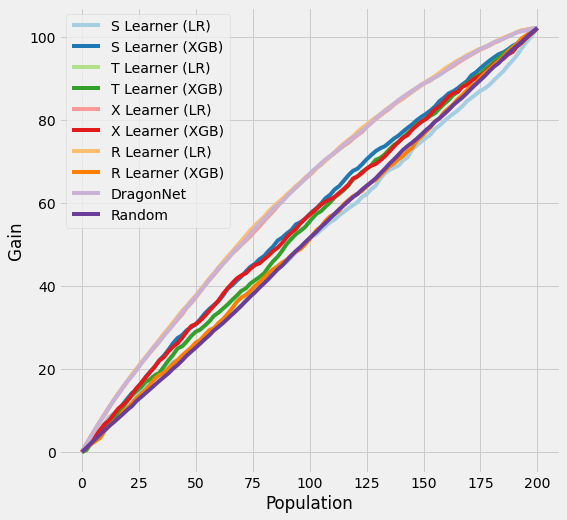
[ ]: